How Poetiq's Meta-System Boosts AI Coding Performance Without Fine-Tuning
Poetiq has unveiled a groundbreaking approach to improving large language model (LLM) performance on coding tasks. Instead of fine-tuning models or accessing their internal workings, their Meta-System automatically constructs and optimizes an inference harness—a supporting framework that manages how models process inputs and outputs. This technique proved remarkably effective on the demanding LiveCodeBench Pro benchmark, boosting results across multiple models, including a dramatic leap for Gemini 3.1 Pro that surpassed even Google's own specialized reasoning model. Below, we break down the key findings and implications.
What is Poetiq's Meta-System and How Does It Work?
The Meta-System is an automated framework designed to build a custom inference harness for any LLM without requiring fine-tuning or access to the model's internal parameters. Instead, it treats the model as a black box and optimizes the external environment—prompt structures, output parsing, memory management, and runtime constraints—to achieve superior results. The system uses recursive self-improvement, meaning it iteratively tests and refines the harness based on performance feedback. In essence, it acts like a sophisticated adapter that amplifies a model's inherent capabilities by optimizing how it interacts with data and constraints. This design makes the Meta-System model-agnostic, allowing the same harness to be applied to different LLMs without modification, provided they share a common API. The result is a plug-and-play performance boost that can be deployed without retraining or costly infrastructure changes.
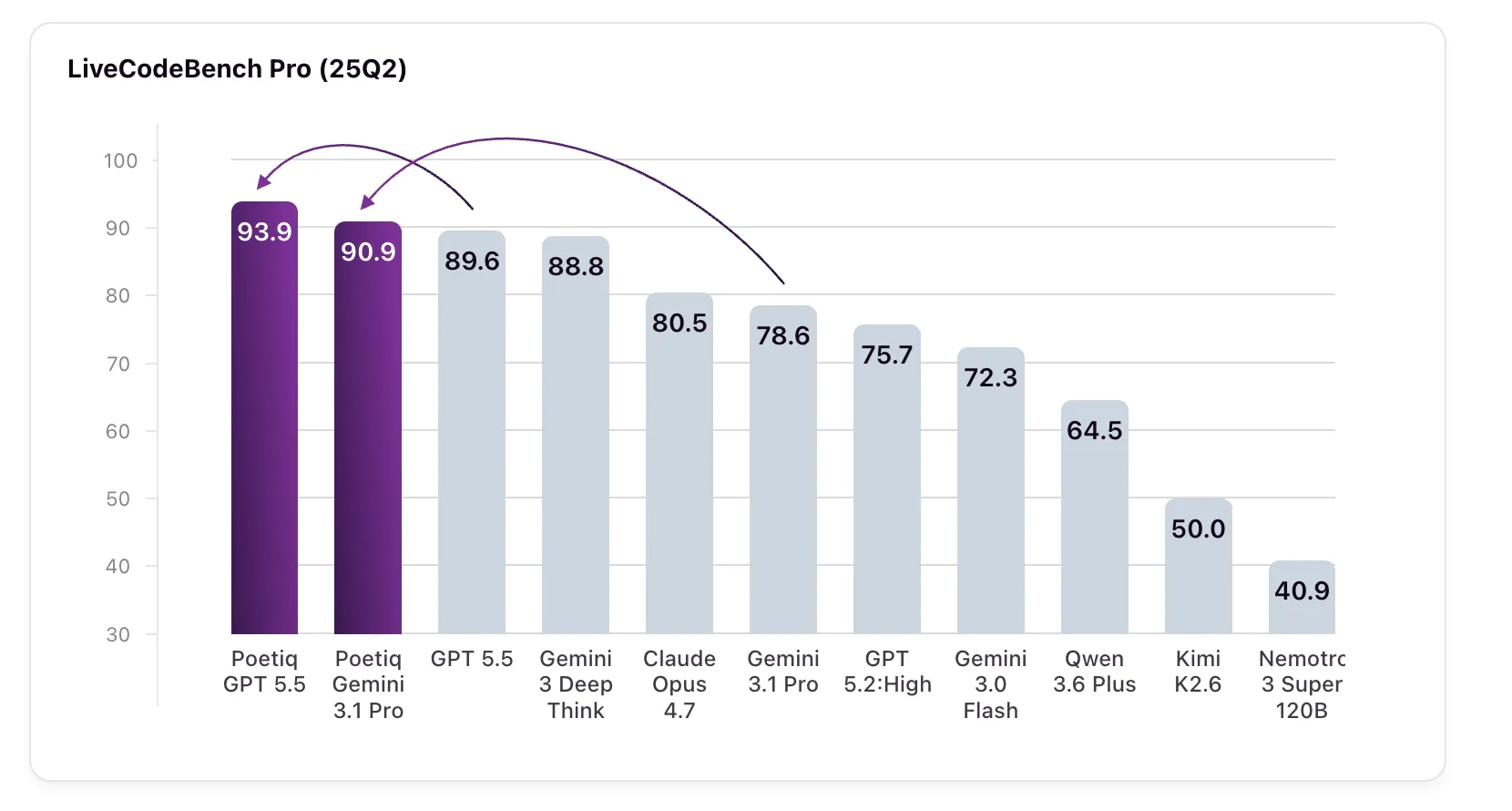
What Results Did Poetiq Achieve on LiveCodeBench Pro?
Poetiq's tests on LiveCodeBench Pro (LCB Pro) delivered impressive gains. For GPT 5.5 High, the baseline score of 89.6% climbed to 93.9% after applying the Meta-System's harness—a 4.3 percentage point increase. Even more striking was Gemini 3.1 Pro, which jumped from 78.6% to 90.9%, a rise of 12.3 points. This new score actually outperformed Google's own Gemini 3 Deep Think model, which achieved 88.8% but is not publicly accessible via API, making its results difficult to verify independently. The harness was optimized specifically on Gemini 3.1 Pro, yet it also improved GPT 5.5 High and other models without any changes, confirming the system's model-agnostic nature. These results suggest that intelligent inference infrastructure can unlock hidden potential in existing LLMs, challenging the assumption that only better training data or larger models drive progress.
What Is LiveCodeBench Pro and Why Does It Matter?
LiveCodeBench Pro is a rigorous coding benchmark designed to resist data contamination and overfitting—two common pitfalls that can inflate scores on static benchmarks. Unlike many tests, LCB Pro pulls problems from active competitive programming competitions and withholds the official solution code. Instead, it validates submitted solutions against a comprehensive test suite that checks not only correctness but also memory usage and runtime performance. The benchmark focuses exclusively on C++ challenges, emphasizing creative problem-solving and efficient procedural logic. Additionally, the problem set is continuously updated, ensuring that models cannot memorize answers. This makes LCB Pro a strong indicator of genuine coding capability, as it tests a model's ability to generate novel, high-quality code under strict constraints. Poetiq's choice of this benchmark underscores their commitment to demonstrating real-world improvements that go beyond simple pattern matching.
How Does Poetiq Classify LLM Tasks and Why Focus on Coding?
Poetiq categorizes LLM performance into three distinct task types: Reasoning (measured by ARC-AGI), Retrieval (measured by Humanity's Last Exam, or HLE), and Coding. They view coding as the most commercially relevant today, blending reasoning and retrieval with the generation of specialized procedural logic. Coding also presents unique challenges—it requires precise syntax, algorithmic thinking, and adherence to constraints—making it an ideal stress test for a system that aims to boost performance without modifying the model itself. By focusing on coding, Poetiq can demonstrate that their Meta-System directly addresses practical needs in software development, where even modest gains in code quality or efficiency translate to significant productivity improvements. The coding initiative also serves as a proof of concept for the broader applicability of the harness approach across other domains.

What Were the Three Objectives of Poetiq's Coding Initiative?
Poetiq's research had three clear goals. First, to prove that an intelligent harness could improve model efficacy without fine-tuning or special access to the model's internals. Second, to validate that the Meta-System could achieve recursive self-improvement in constructing the harness automatically, meaning the system learns from its own attempts to create better harnesses over time. Third, to demonstrate that the resulting harness is model-agnostic—that it works on any compatible LLM without modification. According to their published results, all three objectives were met. The first objective was satisfied by the significant score improvements. The second was demonstrated through the iterative optimization process that produced the final harness. The third was confirmed when the same harness boosted performance on models it was not specifically trained on, such as GPT 5.5 High. This triple validation strengthens the case for inference harnesses as a new paradigm in LLM deployment.
What Exactly Is a Harness and Why Does It Matter?
In the context of LLM inference, a harness refers to the infrastructure that manages how a model receives prompts, processes outputs, and handles constraints like time and memory limits. It can include components such as dynamic prompt engineering, output validation, error handling, and resource allocation. While often overlooked, the harness plays a critical role in real-world performance. A well-designed harness ensures that the model's strengths are leveraged and its weaknesses mitigated. Poetiq's Meta-System automatically builds this harness, optimizing it for a given benchmark or task without any human intervention. The significance lies in its model-agnostic nature: once built, the same harness can be applied to various models, effectively creating a universal performance boost. This approach offers a cost-effective alternative to fine-tuning or hardware upgrades, potentially democratizing access to high-performance AI for smaller teams and organizations.